lab3 pgtbl的难度陡增。而且发现一个特点,其实只看实验文档所说的章节往往是不够的,而且越来越不够。前面的章节要好好复习,后面的章节可能也要看看。
第一题依然是热身难度,但是第二题开始完全不知道怎么下手,盲点过多。
懵逼了一整天,参考了其他人的经验才调好了第二题的细节。只好先放下,先把xv6那本书再看一遍。在理解的基础上,再做一遍。
不能急,慢慢来。
===
复习ing,TBC
a programmer's perspective
lab3 pgtbl的难度陡增。而且发现一个特点,其实只看实验文档所说的章节往往是不够的,而且越来越不够。前面的章节要好好复习,后面的章节可能也要看看。
第一题依然是热身难度,但是第二题开始完全不知道怎么下手,盲点过多。
懵逼了一整天,参考了其他人的经验才调好了第二题的细节。只好先放下,先把xv6那本书再看一遍。在理解的基础上,再做一遍。
不能急,慢慢来。
===
复习ing,TBC
进入lab2 syscall,这次的任务是写两个系统调用。
第一个是trace,功能是把程序执行过程中的系统调用都展示出来。trace shell命令已经写好了,在user/trace.c里面,看看就好,不用修改这个文件。
首先,老老实实按照lab的指示,阅读xv6 book的第二章,还有第四章的4.3和4.4 。这里面一个重点是kernel/proc.h里面的proc结构体,其实它就是xv6的进程控制块(PCB Process Control Block,当年在书上学来学去很多遍,不如在代码见识一次)。你需要扩展它,增加一个值用来记录trace mask。你需要的很多信息也都在这个结构体里面。
照葫芦画瓢,在其他syscall的定义文件里,Makefile、kernel/syscall.h、kernel/syscall.c、user/user.h、user/usys.pl里面统统加上trace相关的声明,照着每个文件的格式写就行。
然后功能分布在kernel/proc.c, kernel/syscall.c, kernel/sysproc.c里面。proc.c主要是把trace mask从父进程拷贝到子进程。syscall.c负责打印trace信息。sysproc.c则包含了sys_trace的系统调用本体,逻辑很简单,就是把参数存到proc结构体新增的成员变量里。

也许你需要这个表
char* syscall_names[] = {
"xxx",
"fork",
"exit",
"wait",
"pipe",
"read",
"kill",
"exec",
"fstat",
"chdir",
"dup",
"getpid",
"sbrk",
"sleep",
"uptime",
"open",
"write",
"mknod",
"unlink",
"link",
"mkdir",
"close",
"trace",
"sysinfo",
};
第二个是sysinfo。还是要注意在各个头文件里加好函数声明。在kernel/kalloc.c里定义一个空闲内存的统计函数,很简单,就是遍历那个全局链表kmem,统计个数,然后乘以PGSIZE。在kernel/proc.c里定义一个统计进程状态不等于UNUSED的进程个数,遍历全局变量proc数组一个个判断、累加。至于把struct sysinfo从内核拷贝到用户空间,直接在代码库里搜索copyout有大量范例,照抄即可,easy peasy。
最早国产的操作系统课基本是原理课,很少有上手做点东西的机会,当年学完还是很遗憾的。后来国内的课程发展很快,比如清华大学和哈工大的课都有设计比较好的实验,但是他们的课都有莫名其妙的门槛,比如学堂在线的实验环境引导已经实质上失效了(是mooc课程没有即时更新,其实文档和配套代码都很全),网易云课堂没有self paced模式,只能等下一次开课。
还好顺藤摸瓜找到了MIT操作系统课6.S081的页面,发现了宝藏。最新的2020年教学录像、课件、lab代码一应俱全,甚至还有自助判分工具。
做了一下lab1 util,难度适中,上手比较轻松。那本xv6的手册写的极其精练,一下子理清了很多以前模糊的概念。宝藏课程宝藏课程。
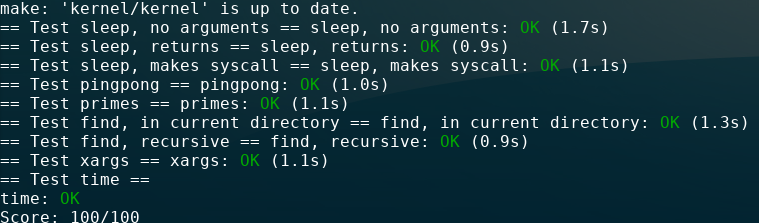
MIT lab的引导写的非常详尽,一步一步照着做就行。不过有几道题的细节还是有点麻烦。比如用CSP(就是Golang用的并发模型,你赚到了!)来写的primes,如果不注意在主进程和子进程把没用到pipe的读、写fd关闭,你先遇到的并不是xv6的fd数量限制,而是子进程读取pipe时会阻塞,因为写的那端没关闭,数据已经读完了但会一直在等,程序就不往下跑了。xargs也有个小细节,就是执行exec调用,argv数组要以命令本身开始,用0结束(也就是NULL),see example。
总之真的是比较愉快的体验。这个时代资源随手可得,现在的孩子太幸福了。